本文共 4761 字,大约阅读时间需要 15 分钟。
- 何恺明、陈鑫磊提出实例分割框架TensorMask,媲美Mask R-CNN
- 无人车创企RoadStar.ai进入清盘阶段
- 华为年报:总收入突破千亿美元大关,研发支出过千亿人民币
- 明略数据完成20亿元D轮融资,腾讯领投
- 英伟达发布全市监控数据集“CityFlow”
- SkelNetOn挑战赛从图像、点云和参数表示中提取骨架
- 河南大学发布中国商店街景数据集ShopSign,含超过25,000张图片
- nuTonomy发布自动驾驶汽车数据集nuScenes,含超过1000个场景
- 谷歌机器人每小时可抛掷500件物品
何恺明、陈鑫磊提出实例分割框架TensorMask,媲美Mask R-CNN
近日,Facebook的陈鑫磊、何恺明等人提出一种通用的实例分割框架TensorMask,弥补了密集滑动窗口实例分割的短板。
在COCO数据集上的测试显示,TensorMask的效果可以和实例分割的主流方法——Mask R-CNN相媲美。在COCO数据集上进行实例分割检测可以发现,TensorMask在test-dev上的平均精度达到了35.5,与Mask R-CNN的36.8非常接近。
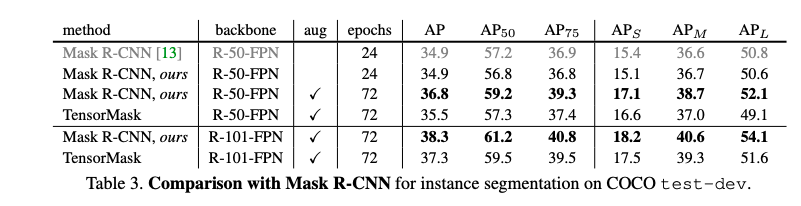
在定量和定性上,TensorMask均接近Mask R-CNN。
论文链接:
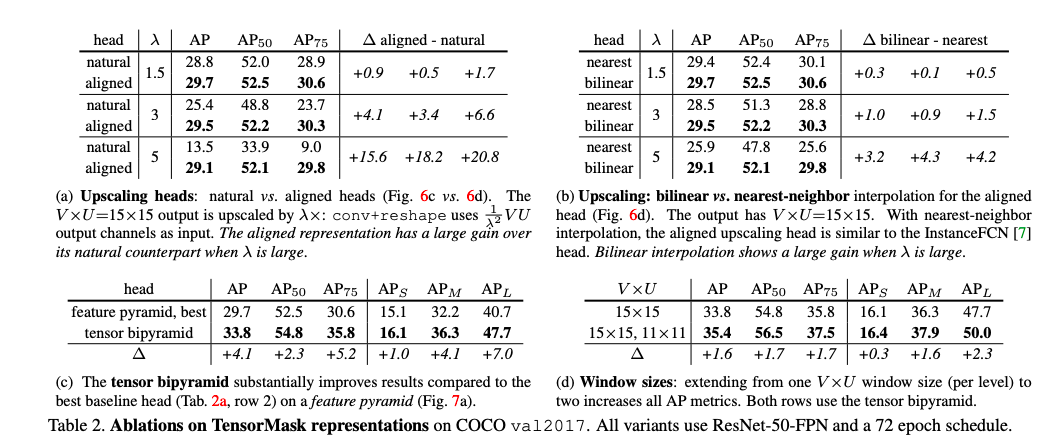
TensorMask的核心变化是,用结构化的高维张量表示一组密集滑动窗口中的图像内容。
它包含两部分:1. 预测蒙版的Head,负责在滑动窗口中生成蒙版;2. 进行分类的Head,负责预测目标的类别。
无人车创企RoadStar.ai进入清盘阶段
近日,(深圳星行科技)已进入清盘状态,创始人单飞,公司和投资方进入仲裁阶段,办公室已关停。
RoadStar.ai被清盘疑似起因于创始人内讧,另外还有公司内部贪污腐败、技术研发停滞、产品迟迟不落地等诱因。投资方随后介入协调,最终具有国资背景的投资方要求清盘退出。公司创始人(最大股东)佟显乔、周光和衡量据说已离开公司。
在这之前,RoadStar.ai还是一家明星无人车创企,2017年获得数千万美元种子轮融资,2018年5月份宣布获得1.28亿美元A轮融资,创下无人驾驶单轮融资新纪录。时隔半年,这家明星公司就迅速陨落。
华为2018年报:总收入突破千亿美元大关,研发支出过千亿人民币
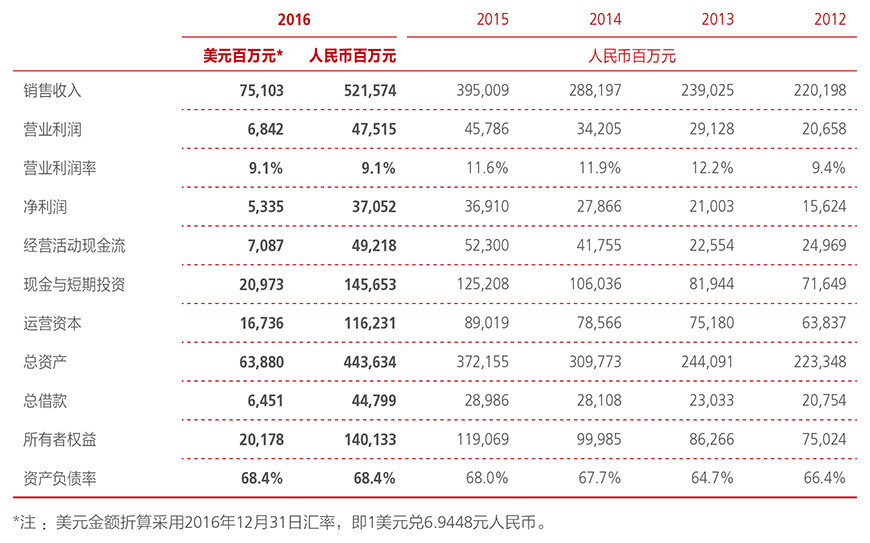
3月29日,华为公布2018 年财报。财报显示,华为 2018 年总收入 7212 亿元(约合 1070 亿美元),同比增长 19.5%,净利润 593 亿元,同比增长 25.1%,这是华为年收入首次突破千亿美元大关。经营活动现金流为 747 亿元人民币;研发费用 1015 亿元,占收入的 14.1%。
其中,消费者业务收入为 3489 亿元,同比增长 45.1%;企业业务收入为 744 亿元,同比增长 23.8%;运营商业务收入 2940 亿元,同比减少 1.3%。过半收入来自于中国市场,其次是欧洲、中东、非洲,亚太地区和美洲,总体来看,华为在上述区域的营收均呈现增长趋势。
明略数据完成20亿元D轮融资,腾讯领投
3月27日,明略数据宣布完成20亿元D轮融资,腾讯再度领投,金拓资本、华兴新经济基金、中航信托跟投。
明略科技董事长兼CEO吴明辉表示,此次融资完成,首要任务就是继续加强科学院,在各个实验室中继续补充各个层次人才,提升研发实力。未来,明略将聚焦三大方向:
打造中国领先的一站式企业级AI产品与服务平台;
在大AI理念下推动HAO智能模型落地;
加强明略科学院实力,从产品创新到技术创新。
去年4月,明略宣布华兴、腾讯领投的10亿元C轮融资,估值超14亿美元,跻身独角兽行列。
英伟达发布全市监控数据集“CityFlow”
英伟达、圣何塞州立大学和华盛顿大学联合发布数据集CityFlow,这个数据集可以帮助研究人员开发用于监控和跟踪城市周围车辆的算法。
CityFlow数据集:包含从放置在美国城市10个交叉路口的40台摄像机收集的时长3.25小时的视频。“该数据集涵盖了多种不同的位置类型,包括交叉路口、道路路面和高速公路”。CityFlow包含666辆车的超过229,680个边界框,如汽车、公共汽车、皮卡车、货车、SUV等。每个视频的分辨率至少为960像素,“大多数”的帧速率为10 FPS。
子数据集:CityFlow ReID:这个数据子集用于重新识别从一个摄像头中消失,又出现在另一个摄像头中的行人和车辆。该数据子集包括56,277个边界框。
Baseline:CityFlow附带一组Baseline,用于执行以下任务:
行人重新识别。
车辆重新识别。
单摄像机跟踪不同的对象。
多摄像机跟踪给定对象。
重要性:无处不在的监控:我很高兴看到报纸上越来越多地在讨论监控系统的应用和潜在问题,监控系统显然可以用来提高城市交通系统的效率(和安全性),但也会用于当地警局、国家和国际情报收集系统。这会产生很多分歧,我很高兴看到更多的研究人员花时间讨论监控系统的这些方面。
阅读更多:CityFlow:城市规模的多目标多相机车辆跟踪和重新识别基准(
SkelNetOn挑战赛从图像、点云和参数表示中提取骨架
多个研究机构推出了“SkelNetOn”数据集和挑战赛,旨在“利用现有及开发新的深度学习架构进行形状理解”。该挑战赛涉及对象的几何建模,这个问题非常有用,因为解决这一问题的技术可以自然地生成“用于建模、合成、压缩和分析形状的紧凑、直观的表示”。
三个领域中的三个挑战:每个SkelNetOn挑战都附带自己的数据集,包括1,725个配对图像/点云/对象和骨架的参数化表示。
重要性:数据集有助于人工智能研究进展,能够从图像中巧妙地推断出二维和三维架构将释放应用程序的潜力,从依赖计算机的Kinect风格接口,到能够廉价生成(基本)骨架模型,可用于媒体制作,例如视频游戏。
作者“相信SkelNetOn有可能成为深度学习和形状理解交叉的基础基准…最终,我们预计这种深度学习方法可被用来抽象用于生成模型的表达和层次表示的参数以及程序化“。
阅读更多:SkelNetOn 2019数学和深度学习的形状理解挑战(
河南大学发布中国商店街景数据集ShopSign,含超过25,000张图片

… ShopSign数据集花费了两年多的时间来收集,并包含五个类别的标志…
中国研究人员创建了一个中国商店街景数据集ShopSign。研究人员指出,中国商店标志往往是长度不一,使用材料和风格、背景不同;相比之下,美国、意大利和法国等地的商店标志更加标准化。该数据集将帮助人们训练与(某些)中国标志相对应的自动字幕系统,并可能用于二次应用,例如使用生成模型创建合成的中国商店标志。
主要统计数据:
25,362:中国商店牌匾图像数量。
4,000:夜间拍摄的图像。
2,516:从侧面和正面视角拍摄的商店标志的成对图像。
50:用于收集数据集的不同类型的相机,图像发生自然变化。
2.4年:收集数据集所花费的时间。
\u0026gt;10:图像的位置,包括上海、北京、内蒙古、新疆、黑龙江、辽宁、福建、商丘、周口,以及河南省的几个城市地区。
5:“特殊类别”、“硬图像”,标志有木质、变形、暴露、镜像或模糊的背景。
196,010:数据集中的文本行。
626,280:数据集中的中文字符。
重要性:创建不是主要用英语编写的图像开放数据集将有助于AI多样化,使世界其他地区的研究人员更容易在与他们相关的环境中构建工具和进行研究。我迫不及待地想看看ShopSigns可以包含各种语言,涵盖全世界的商店标志(然后我希望有人用它训练一个Style / Cycle / Big-GAN来生成合成的街景艺术!)。
获取数据:
阅读更多:ShopSign:中国商店的街景多样化场景文本数据集
nuTonomy发布自动驾驶汽车数据集nuScenes,含超过1000个场景
自动驾驶汽车公司(由APTIV所有)nuTonomy发布了nuScenes,一个可用于开发自动驾驶汽车的多模式数据集。
数据集:nuScenes中的数据由超过1,000个不同场景组成,每个场景长度约为20秒,每个场景都有从nuTonomy自动驾驶车辆上的五个雷达、一个激光雷达和六个基于摄像头的传感器收集的数据。
该数据集包括在旧金山和新加坡收集的时长约5.5小时的视频,包括雨、雪中的场景。nuScenes是“首个从整套传感器获得360°覆盖的数据集,也是首个包含雷达数据的AV数据集,以及首个使用获得AV批准用于公共道路数据收集的数据集。”该数据集的灵感来自自动驾驶汽车数据集KITTI(
有趣的场景:这个数据集包含很多具有挑战性的场景,包括在交叉路口和建筑工地的导航,救护车和动物等罕见目标出现,以及行人乱穿人行道等危险情景。
具有挑战性的任务:nuScenes附带一些内置任务,包括计算数据集中10类对象的边界框,属性和速度。
重要性:由于商业价值极高,自动驾驶汽车数据集非常少。nuScenes将让研究人员更好地了解开发和部署自动驾驶汽车技术所需的数据属性。
阅读更多:
nuScenes:一个自动驾驶多模式数据集(
nuScenes导航示例场景:
GitHub:
注册并下载完整数据集:
谷歌机器人每小时可抛掷500件物品

谷歌的研究人员已经教过机器人把物品从一个容器扔到另一个容器,来运输(粗略模拟)仓库周围的物体。这样的系统显示出AI技术在应用中的强大功能,但在实际部署中却有很高的故障风险。
机器人的三个模块:机器人随附一个感知模块,一个抓取模块和一个投掷模块。
感知模块帮助机器人看到对象并计算关于对象的3D信息。
抓取模块试图预测拾取对象的成功率。
投掷模块试图预测“预定义的抛掷物的释放位置和速度”,并借助手写物理控制器进行预测。它使用此信号以及残余信号来预测要使用的适当速度。
Residual physics:系统使用手写物理控制器和一个学习机器人操控参数的函数来学习投掷对象。通过这种方法,研究人员产生了“更广泛的数据驱动校正,可以补偿嘈杂的观测以及未明确建模的动态”。
效果如何?他们在“UR5”机器人手臂上进行测试,该手臂使用RG2抓手“挑选并投掷80多种不同玩具积木、假水果、装饰物品和办公物品”。他们进行了三种baseline和人类测试。测试表明,与纯回归或基于物理的baseline相比,本文的“Residual physics”技术是最有效的。
机器人在抓握和投掷物品时接近人的表现,人类的平均成功投掷率为80.1%(正负10左右),而这个机器人系统的投掷成功率为82.3%。
该系统每小时可以拾取和抛掷514件物品(不包括未能抓取的物品),比其他技术更胜一筹,比如Dex-Net或Cartman。
重要性:抛掷机器人展示了混合AI系统的强大功能,它将学习的组件与包含领域知识的手写算法(如物理控制器)配对。这对Rich Sutton等认为“计算是人工智能研究的主要因素”的看法提出了挑战。然而,值得注意的是,考虑到在实际部署之前系统在还需要很长的训练阶段,抛掷机器人在实际部署中许多功能还依赖于低成本的计算。
此外,制造商一般要求工厂搬运货物的成功率为99.9N%(甚至99.99N%),而不是80.N,该系统82.3%表现还有待改善。
阅读更多:
TossingBot:使用 Residual Physics学习抛掷任意物体
作者 Jack Clark 有话对 AI 前线读者说:我们对中国的无人机研究非常感兴趣,如果你想要在我们的周报里看到更多有趣的内容,请发送邮件至:jack@jack-clark.net。
转载地址:http://bvkix.baihongyu.com/